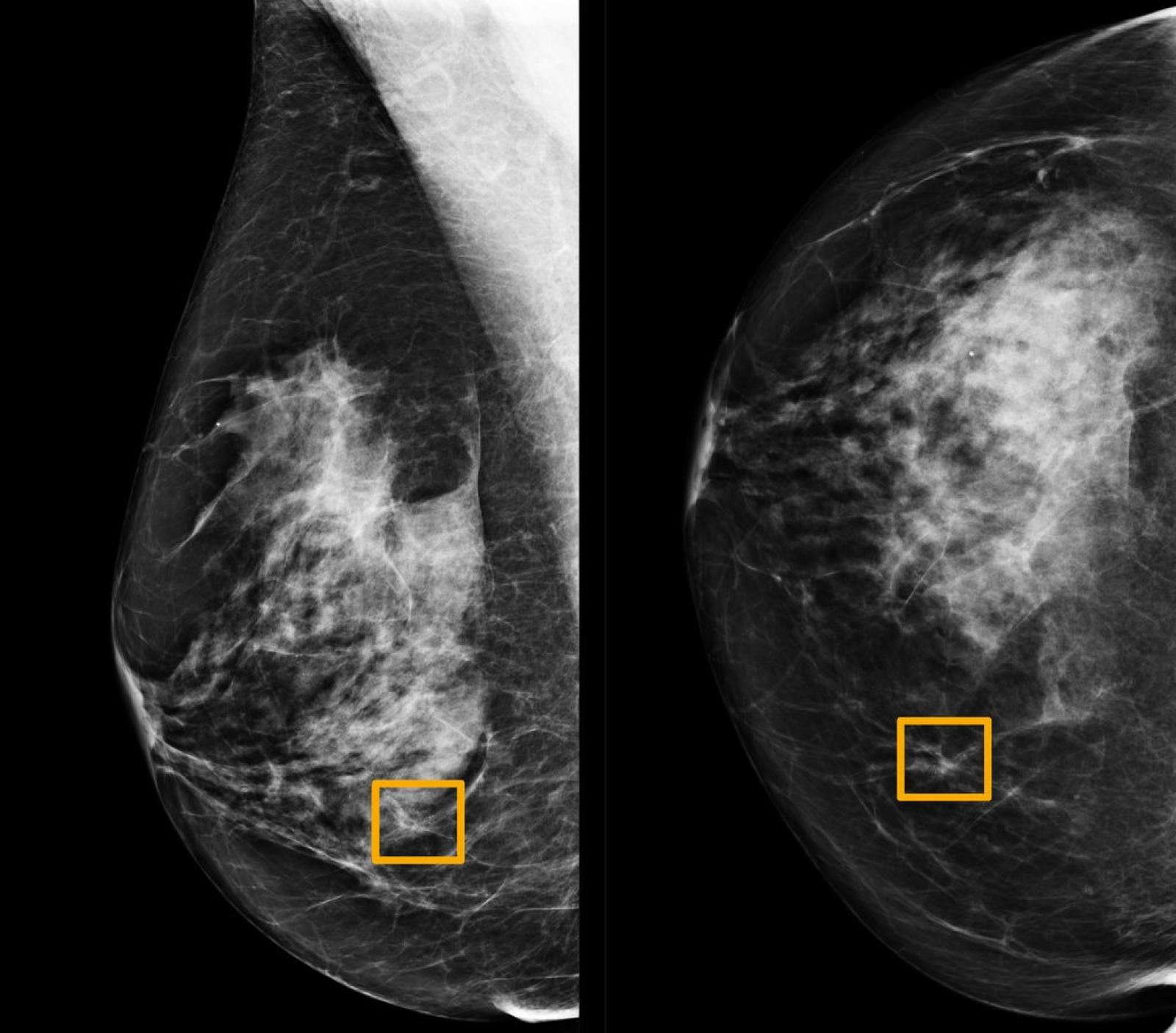
Immagine mammografica contenuta nel campione utilizzato dallo studio "International evaluation of an AI system for breast cancer screening", pubblicato da Google su Nature a gennaio del 2020. I rettangoli gialli indicano le aree in cui il sistema di intelligenza artificiale ha individuato formazioni tumorali che i sei radiologi esperti coinvolti nello studio non sono stati in grado di riconoscere.
Due settimane fa un gruppo di ricercatori cinesi
ha pubblicato
sulla rivista Nature Communications uno studio in cui mostra
le performance di un sistema di intelligenza artificiale nel
diagnosticare la COVID-19 a partire dalle immagini di tomografia
computerizzata dei polmoni, distinguendola da altre tre patologie:
le polmoniti causate dall'influenza stagionale, le polmoniti non virali
e altri tipi di lesioni diverse dalle polmoniti. Si tratta solo
dell'ultimo di una serie di sistemi di intelligenza artificiale
messi a punto negli ultimi mesi per diagnosticare la COVID-19,
che potrebbero diventare utili se i sistemi sanitari sottoposti
a pressione esagerata non fossero più in grado di effettuare
tempestivamente i test molecolari (quelli che cercano tracce dell'RNA
virale nei campioni prelevati tramite tampone naso-faringeo).
Questi sistemi di lettura automatizzata
potrebbero poi essere modificati per funzionare anche su
radiografie polmonari,
un metodo diagnostico facilmente disponibile anche nei Paesi meno
sviluppati.
Non solo. Potrebbero servire anche a individuare con un po' di anticipo i pazienti che andranno incontro a un decorso più severo e che necessiteranno di essere intubati, permettendo così agli ospedali di gestire meglio le loro risorse. A fine settembre uno di questi sistemi, sviluppato dalla società Dascena di San Francisco, ha ottenuto l'approvazione per uso in caso di emergenza da parte della Food and Drug Administration, l'agenzia del farmaco statunitense.
I sistemi di intelligenza artificiale per la diagnosi e il triage dei casi di COVID-19 sono solo gli ultimi esempi di una serie di algoritmi di machine learning che hanno trovato numerose applicazioni nelle attività di diagnostica per immagini, a cominciare dalla diagnosi dei tumori. Analizzare immagini mammografiche o biopsie di diversi tipi di tessuto alla ricerca di formazioni cellulari anomale o veri e propri tumori si è dimostrato un compito particolarmente facile per questo tipo di algoritmi, che spesso hanno superato in bravura radiologi e patologi con anni di esperienza. Il caso più studiato è sicuramente quello del tumore al seno, ma sono stati ottenuti risultati importanti anche per i tumori del polmone e della pelle.
L'obiettivo è classificare l'immagine diagnostica in un numero finito di categorie. Nei casi semplici sarà sufficiente discriminare fra solo due gruppi, sano o malato, in quelli più complessi bisognerà considerare diversi tipi di anomalie, da quelle benigne a quelle più aggressive. Il successo dell'intelligenza artificiale è arrivato proprio con lo sviluppo di algoritmi particolarmente capaci in questa attività di classificazione delle immagini.
Una rete neurale è costituita da una serie di strati ciascuno contenente un certo numero di nodi. I nodi sono ispirati ai neuroni del nostro cervello che ricevono informazione dai neuroni adiacenti tramite le sinapsi, le elaborano e le trasmettono a loro volta. I nodi, come neuroni artificiali riprodotti a computer, ricevono informazione dai nodi dello strato precedente e la trasmettono a quelli dello strato successivo. Ma le connessioni tra i nodi della rete non sono tutte uguali, la loro intensità cambia, ed è proprio l'insieme di queste intensità che viene regolata durante la fase di allenamento affinché la rete sia in grado di classificare nel modo più corretto possibile. Immaginiamo di dare in pasto alla rete neurale nel suo primo strato, quello di input, la fotografia di un cane. Per farlo tradurremo l'immagine in un insieme di valori numerici, i valori dei pixel che la compongono. L'informazione si propagherà attraverso la rete neurale secondo le intensità delle diverse connessioni e arriverà nello strato finale, o di output, che ci darà una risposta binaria 'cane' o 'non cane'. Faremo lo stesso con tutte le immagini contenute nel nostro campione di allenamento e conteremo quante volte la rete dà la risposta esatta e quante volte quella sbagliata. All'inizio la rete sarà poco efficiente e sbaglierà spesso. Per cercare di migliorare dovremo intervenire sull'intensità delle connessioni tra i nodi dei vari strati della rete. Ma come? Si tratta di un numero enorme di parametri, soprattutto per architetture profonde (deep) che hanno molti strati nascosti. Capire come variare questi parametri per diminuire l'errore è un problema numericamente assai complicato. Viene in soccorso un metodo matematico chiamato back-propagation, che sfrutta proprio la struttura a strati della rete neurale ripercorrendola a ritroso dall'output all'input individuando il modo giusto in cui girare le manopole delle connessioni per migliorare la performance della rete. Una volta terminata la fase di allenamento, la nostra rete avrà imparato come riconoscere 'cani' da 'non cani' e potrà essere usata su nuove immagini.
Questo tipo di sistemi è estremamente flessibile perché non utilizza alcuna forma di ragionamento astratto sulle caratteristiche di un cane. Non cerca cioè le orecchie, non conta le zampe, ma impara dalle immagini che gli forniamo durante l'allenamento. Per questo motivo trova applicazione in diversi contesti, tra cui quello medico.
Il sistema che abbiamo appena descritto potrebbe dunque rivelarsi utile nel momento in cui si verificasse una cosiddetta twindemic, l'aggravarsi simultaneo dell'epidemia di SARS-CoV-2 e del virus dell'influenza stagionale e i centri clinici non fossero più in grado di ricorrere ai test molecolari per discriminare tra le due patologie.
Anche nei programmi di screening mammografico, il passo diagnostico precedente alla biopsia, il tasso di errore non è trascurabile. La American Cancer Society stima che il test ha il 20% di falsi negativi, tumori che non vengono diagnosticati. Per quanto riguarda i falsi positivi, formazioni benigne scambiate per tumori, sempre la American Cancer Society stima che il 50% delle donne che si sottopongono annualmente a una mammografia avrà un falso positivo nell'arco di 10 anni di indagini. È stato quindi accolto con favore lo studio pubblicato da Google all'inizio di quest'anno sulla rivista Nature dal titolo "International evaluation for an AI system for breast cancer screening". L'articolo presenta le performance di un algoritmo per l'analisi delle immagini mammografiche. Per farlo i ricercatori hanno utilizzato un campione di immagini ottenute da 76 mila donne nel Regno Unito e 15 mila donne negli Stati Uniti per cui sono noti sia la diagnosi pronunciata dal radiologo che ha valutato per primo la mammografia sia il decorso di salute o malattia. Dopo aver allenato l'algoritmo su un sottoinsieme delle immagini, lo hanno testato sull'insieme restante, confrontando i risultati con la prima diagnosi del radiologo e con la 'vera' diagnosi dedotta dai decorsi di salute o malattia. Da questo confronto è emerso che: per il campione statunitense l'intelligenza artificiale riduce del 9,4% la percentuale di falsi negativi e del 5,4% quella di falsi positivi, mentre per il campione britannico la riduzione è del 2,7% e dell'1,2% rispettivamente. I ricercatori hanno poi effettuato una sfida tra l'algoritmo e sei radiologi esperti a cui sono state sottoposte 500 mammografie, insieme ad alcune informazioni che sono normalmente disponibili come l'età della paziente e altri screening precedenti. Anche in questo confronto il sistema si comporta meglio dei radiologi, anche se esistono dei casi di tumore diagnosticati solo dai radiologi e non dall'intelligenza artificiale e viceversa.
Proprio questo tipo di alleanza tra medici e algoritmi potrebbe portare beneficio a entrambi i settori. Come si legge in un editoriale pubblicato sulla rivista Nature un paio di anni fa, c'è bisogno che questi strumenti vengano testati in contesti reali e validati da studi clinici rigorosi. Molti degli studi che abbiamo citato sono realizzati in condizioni molto particolari e diverse da quelle della reale pratica clinica. Ad esempio, in alcuni casi ai radiologi viene concesso pochissimo tempo per analizzare le biopsie. In altri vengono considerate solo immagini prodotte da un certo strumento diagnostico su un certo campione di pazienti e questo potrebbe portare distorsioni quando l'algoritmo viene utilizzato per classificare immagini raccolte da altri dispositivi. Bisogna evitare, continua l'editoriale, di creare dei precedenti negativi che porterebbero la comunità medica a maturare scetticismo verso questi sistemi e allo stesso tempo potrebbero danneggiare i pazienti.
In una intervista al New York Times, la dottoressa Constance Lehman, direttrice della divisione di breast imaging al Massachusetts General Hospital, racconta una storia che potrebbe servire da ammonimento per il futuro. Alla fine degli anni '90 divenne di uso comune negli Stati Uniti la tecnologia CAD, computer-aided detection, un sistema approvato dalla FDA per aiutare i radiologi nella lettura delle mammografie. Alcuni direttori di ospedale esercitarono pressione sui loro dipendenti perché lo utilizzassero il più possibile anche se non lo ritenevano utile, solo perché così potevano vendere prestazioni più costose ai loro pazienti. Studi successivi hanno dimostrato che il CAD non solo non aumentava l'accuratezza della diagnosi ma in alcuni casi la aveva addirittura peggiorata.
Non solo. Potrebbero servire anche a individuare con un po' di anticipo i pazienti che andranno incontro a un decorso più severo e che necessiteranno di essere intubati, permettendo così agli ospedali di gestire meglio le loro risorse. A fine settembre uno di questi sistemi, sviluppato dalla società Dascena di San Francisco, ha ottenuto l'approvazione per uso in caso di emergenza da parte della Food and Drug Administration, l'agenzia del farmaco statunitense.
I sistemi di intelligenza artificiale per la diagnosi e il triage dei casi di COVID-19 sono solo gli ultimi esempi di una serie di algoritmi di machine learning che hanno trovato numerose applicazioni nelle attività di diagnostica per immagini, a cominciare dalla diagnosi dei tumori. Analizzare immagini mammografiche o biopsie di diversi tipi di tessuto alla ricerca di formazioni cellulari anomale o veri e propri tumori si è dimostrato un compito particolarmente facile per questo tipo di algoritmi, che spesso hanno superato in bravura radiologi e patologi con anni di esperienza. Il caso più studiato è sicuramente quello del tumore al seno, ma sono stati ottenuti risultati importanti anche per i tumori del polmone e della pelle.
L'obiettivo è classificare l'immagine diagnostica in un numero finito di categorie. Nei casi semplici sarà sufficiente discriminare fra solo due gruppi, sano o malato, in quelli più complessi bisognerà considerare diversi tipi di anomalie, da quelle benigne a quelle più aggressive. Il successo dell'intelligenza artificiale è arrivato proprio con lo sviluppo di algoritmi particolarmente capaci in questa attività di classificazione delle immagini.
Le reti neurali profonde
Si tratta delle cosiddette convolutional neural network, un particolare tipo di reti neurali profonde, che hanno letteralmente rivoluzionato il campo della visione artificiale. La pietra miliare del settore è AlexNet, l'algoritmo sviluppato da George Hinton, premio Turing 2018, e due sue studenti nel 2012, che vinse di misura nella competizione sul riconoscimento delle immagini chiamata ImageNet Large Scale Visual Recognition Challenge. L'articolo che descriveva il funzionamento e le performance di AlexNet venne presentato per la prima volta nel 2012 durante la più importante conferenza annuale sull'intelligenza artificiale, la Conference on Neural Information Processing Systems, ed è considerato uno dei lavori più influenti nell'area. A oggi è stato citato più di 72 mila volte secondo secondo Google Scholar.Una rete neurale è costituita da una serie di strati ciascuno contenente un certo numero di nodi. I nodi sono ispirati ai neuroni del nostro cervello che ricevono informazione dai neuroni adiacenti tramite le sinapsi, le elaborano e le trasmettono a loro volta. I nodi, come neuroni artificiali riprodotti a computer, ricevono informazione dai nodi dello strato precedente e la trasmettono a quelli dello strato successivo. Ma le connessioni tra i nodi della rete non sono tutte uguali, la loro intensità cambia, ed è proprio l'insieme di queste intensità che viene regolata durante la fase di allenamento affinché la rete sia in grado di classificare nel modo più corretto possibile. Immaginiamo di dare in pasto alla rete neurale nel suo primo strato, quello di input, la fotografia di un cane. Per farlo tradurremo l'immagine in un insieme di valori numerici, i valori dei pixel che la compongono. L'informazione si propagherà attraverso la rete neurale secondo le intensità delle diverse connessioni e arriverà nello strato finale, o di output, che ci darà una risposta binaria 'cane' o 'non cane'. Faremo lo stesso con tutte le immagini contenute nel nostro campione di allenamento e conteremo quante volte la rete dà la risposta esatta e quante volte quella sbagliata. All'inizio la rete sarà poco efficiente e sbaglierà spesso. Per cercare di migliorare dovremo intervenire sull'intensità delle connessioni tra i nodi dei vari strati della rete. Ma come? Si tratta di un numero enorme di parametri, soprattutto per architetture profonde (deep) che hanno molti strati nascosti. Capire come variare questi parametri per diminuire l'errore è un problema numericamente assai complicato. Viene in soccorso un metodo matematico chiamato back-propagation, che sfrutta proprio la struttura a strati della rete neurale ripercorrendola a ritroso dall'output all'input individuando il modo giusto in cui girare le manopole delle connessioni per migliorare la performance della rete. Una volta terminata la fase di allenamento, la nostra rete avrà imparato come riconoscere 'cani' da 'non cani' e potrà essere usata su nuove immagini.
Questo tipo di sistemi è estremamente flessibile perché non utilizza alcuna forma di ragionamento astratto sulle caratteristiche di un cane. Non cerca cioè le orecchie, non conta le zampe, ma impara dalle immagini che gli forniamo durante l'allenamento. Per questo motivo trova applicazione in diversi contesti, tra cui quello medico.
Influenza o COVID-19?
È una rete neurale profonda, in particolare una convolutional neural network come quella di AlexNet, anche il sistema messo a punto dai ricercatori cinesi per diagnosticare COVID-19 e in particolare differenziarlo da altri tipi di lesioni polmonari. Lo studio ha utilizzato le TAC polmonari di oltre 9 mila pazienti raccolte da tre centri clinici a Wuhan e cinque diversi database. Ciascuno di questi database è stato diviso in due campioni contenenti circa 2500 soggetti ciascuno, uno per l'allenamento e uno per il test con uguale distribuzione delle quattro possibili patologie (COVID-19, influenza, polmonite non virale e altre lesioni) e sono state effettuate diverse misure di performance. L'algoritmo ha mostrato buone capacità di discriminazione per tutte e quattro le patologie, con un valore del parametro chiamato Area Under the Curve (o AUC, una misura di accuratezza usata per valutare la bontà degli algoritmi di classificazione) pari al 98%. L'algoritmo è stato poi sfidato da cinque radiologi esperti, sull'analisi di 50 immagini di TAC contenenti 30 casi di COVID-19 e 20 casi di influenza. In questa sfida l'algoritmo ha identificato correttamente il 95% dei casi di influenza (il cosiddetto true positive rate) e ha invece diagnosticato erroneamente come influenza il 17% dei casi di COVID-19 (false positive rate). A confronto il migliore dei 5 radiologi ha ottenuto risultati peggiori, diagnosticando correttamente l'85% dei casi di influenza ed erroneamente il 25% dei casi di COVID-19.Il sistema che abbiamo appena descritto potrebbe dunque rivelarsi utile nel momento in cui si verificasse una cosiddetta twindemic, l'aggravarsi simultaneo dell'epidemia di SARS-CoV-2 e del virus dell'influenza stagionale e i centri clinici non fossero più in grado di ricorrere ai test molecolari per discriminare tra le due patologie.
Tumori al seno
Nel 2015 un gruppo di ricercatori statunitensi ha provato a misurare il grado di accordo all'interno di un gruppo di patologi nell'interpretazione delle immagini di tessuti prelevati durante biopsie mammarie. I tessuti appartenevano a 240 donne, affette da diverse forme di anomalia cellulare: da quelle benigne, a quelle atipiche, al carcinoma duttale in situ (considerato pre-canceroso) fino alle forme invasive (quelle in cui le cellule tumorali superano le pareti dei dotti e invadono il tessuto circostante). Un comitato di tre patologi esperti analizzò le immagini e stabilì una diagnosi consensuale considerata di riferimento. Le immagini vennero quindi mostrate a 115 patologi che si trovarono d'accordo con la diagnosi consensuale solo nel 75,3% dei casi. Il grado di accordo però non risultò uniforme per tutte le categorie tumorali. Per le forme invasive l'accordo raggiunse il 96%, al contrario per le forme atipiche solo il 48%. Come scrive Hannah Fry nel suo libro 'Hello World': "Una probabilità del genere equivale a lanciare una moneta per formulare la diagnosi. Testa e potresti praticare una mastectomia non necessaria. Croce e potresti perdere l'occasione di trattare il cancro nella sua fase iniziale. Insomma, l'impatto può essere devastante. Quando la posta in gioco è così alta, la precisione è ciò che conta di più. E se un algoritmo potesse fare meglio?"Anche nei programmi di screening mammografico, il passo diagnostico precedente alla biopsia, il tasso di errore non è trascurabile. La American Cancer Society stima che il test ha il 20% di falsi negativi, tumori che non vengono diagnosticati. Per quanto riguarda i falsi positivi, formazioni benigne scambiate per tumori, sempre la American Cancer Society stima che il 50% delle donne che si sottopongono annualmente a una mammografia avrà un falso positivo nell'arco di 10 anni di indagini. È stato quindi accolto con favore lo studio pubblicato da Google all'inizio di quest'anno sulla rivista Nature dal titolo "International evaluation for an AI system for breast cancer screening". L'articolo presenta le performance di un algoritmo per l'analisi delle immagini mammografiche. Per farlo i ricercatori hanno utilizzato un campione di immagini ottenute da 76 mila donne nel Regno Unito e 15 mila donne negli Stati Uniti per cui sono noti sia la diagnosi pronunciata dal radiologo che ha valutato per primo la mammografia sia il decorso di salute o malattia. Dopo aver allenato l'algoritmo su un sottoinsieme delle immagini, lo hanno testato sull'insieme restante, confrontando i risultati con la prima diagnosi del radiologo e con la 'vera' diagnosi dedotta dai decorsi di salute o malattia. Da questo confronto è emerso che: per il campione statunitense l'intelligenza artificiale riduce del 9,4% la percentuale di falsi negativi e del 5,4% quella di falsi positivi, mentre per il campione britannico la riduzione è del 2,7% e dell'1,2% rispettivamente. I ricercatori hanno poi effettuato una sfida tra l'algoritmo e sei radiologi esperti a cui sono state sottoposte 500 mammografie, insieme ad alcune informazioni che sono normalmente disponibili come l'età della paziente e altri screening precedenti. Anche in questo confronto il sistema si comporta meglio dei radiologi, anche se esistono dei casi di tumore diagnosticati solo dai radiologi e non dall'intelligenza artificiale e viceversa.
Il pericolo della sovradiagnosi
Lo studio ha attirato anche delle critiche da parte di coloro che temono che il problema della sovradiagnosi possa essere esacerbato dall'utilizzo di questi strumenti. Il fatto è che non sappiamo quali tipi di forme iniziali di tumore al seno evolveranno in tumori invasivi capaci di minacciare la vita di una persona. I dati accumulati in decenni di screening contro i tumori della mammella hanno infatti mostrato che esistono certi tipi di tumori indolenti che l'organismo terrà a bada e non si trasformeranno mai in un rischio per la nostra salute. Ma, purtroppo, al momento della mammografia i medici non sono in grado di capire quale tumore hanno di fronte e tendono a trattarli tutti come potenziali minacce. È per questo che l'efficacia degli screening mammografici nel salvare vite umane è una faccenda molto controversa. E la capacità di un sistema automatizzato di analizzare grandi quantità di immagini e individuare anche le più piccole lesioni senza però poterle classificare più accuratamente potrebbe portare il problema della sovradiagnosi su una scala ancora più grande.Medici assistiti dagli algoritmi
Per ovviare al rischio che abbiamo appena descritto, molti addetti ai lavori suggeriscono un'alleanza tra sistemi di intelligenza artificiale e patologi o radiologi. Gli algoritmi potrebbero essere utilizzati per scremare le immagini e sottoporre agli umani solo quelle su cui sono più incerti. Questa strategia si è dimostrata vincente nella competizione CAMELYON16, in cui patologi e algoritmi si sono confrontati nel classificare le immagini di tessuto linfonodale prelevato da donne con diagnosi di tumore al seno. Le possibili diagnosi erano due: tessuto sano o cancro invasivo della mammella. I patologi senza limiti al tempo di osservazione sono stati in grado di diagnosticare correttamente il 96% delle immagini senza nessun falso positivo. Considerando però il sottoinsieme dei tumori piccoli la loro performance è stata peggiore: ne hanno individuato solo il 73%. Al contrario, la migliore rete neurale della competizione ha identificato il 92,4% dei tumori piccoli, ma con un tasso impressionante di falsi positivi: per ogni immagine 8 gruppi di cellule assolutamente normali sono stati classificati come cancerosi. La sorpresa è arrivata però quando la combinazione di un algoritmo di deep learning con le valutazioni dei patologi ha portato l'accuratezza della diagnosi di questi ultimi dal 96% al 99.5%, mantenendo un tasso nullo di falsi positivi.Proprio questo tipo di alleanza tra medici e algoritmi potrebbe portare beneficio a entrambi i settori. Come si legge in un editoriale pubblicato sulla rivista Nature un paio di anni fa, c'è bisogno che questi strumenti vengano testati in contesti reali e validati da studi clinici rigorosi. Molti degli studi che abbiamo citato sono realizzati in condizioni molto particolari e diverse da quelle della reale pratica clinica. Ad esempio, in alcuni casi ai radiologi viene concesso pochissimo tempo per analizzare le biopsie. In altri vengono considerate solo immagini prodotte da un certo strumento diagnostico su un certo campione di pazienti e questo potrebbe portare distorsioni quando l'algoritmo viene utilizzato per classificare immagini raccolte da altri dispositivi. Bisogna evitare, continua l'editoriale, di creare dei precedenti negativi che porterebbero la comunità medica a maturare scetticismo verso questi sistemi e allo stesso tempo potrebbero danneggiare i pazienti.
In una intervista al New York Times, la dottoressa Constance Lehman, direttrice della divisione di breast imaging al Massachusetts General Hospital, racconta una storia che potrebbe servire da ammonimento per il futuro. Alla fine degli anni '90 divenne di uso comune negli Stati Uniti la tecnologia CAD, computer-aided detection, un sistema approvato dalla FDA per aiutare i radiologi nella lettura delle mammografie. Alcuni direttori di ospedale esercitarono pressione sui loro dipendenti perché lo utilizzassero il più possibile anche se non lo ritenevano utile, solo perché così potevano vendere prestazioni più costose ai loro pazienti. Studi successivi hanno dimostrato che il CAD non solo non aumentava l'accuratezza della diagnosi ma in alcuni casi la aveva addirittura peggiorata.
Per ricevere questo contenuto in anteprima ogni settimana insieme a sei consigli di lettura iscriviti alla newsletter di Scienza in rete curata da Chiara Sabelli(ecco il link per l'iscrizione). Trovi qui il testo completo di questa settimana.
Buona lettura, e buon fine settimana!

