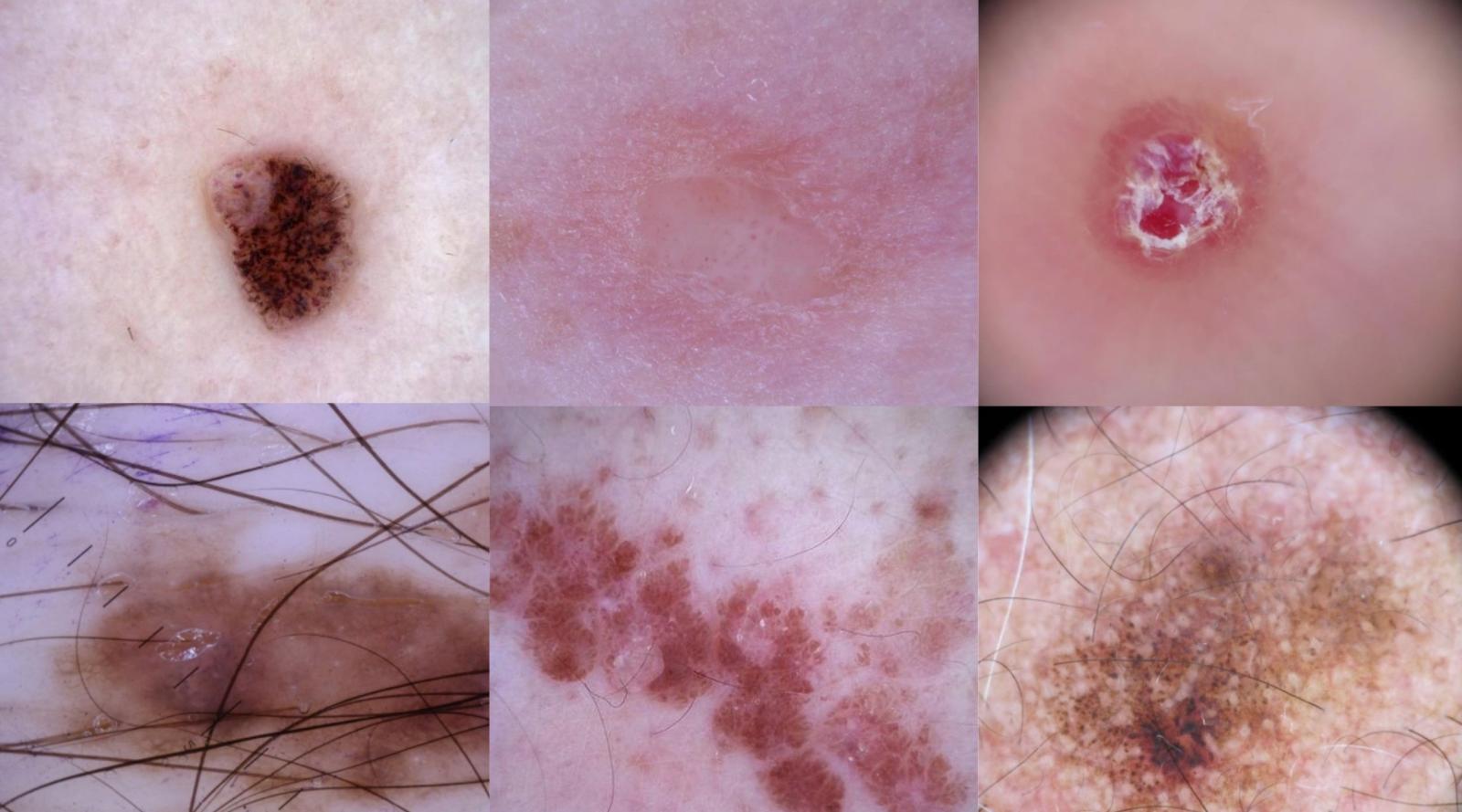
Un mosaico di immagini dermoscopiche dell'archivio ISIC.
Negli ultimi anni, grazie a un particolare tipo di reti neurali profonde, chiamate convolutional neural network e particolarmente efficaci nella classificazione delle immagini, abbiamo letto sui giornali a più riprese che i dermatologi sarebbero presto stati sostituiti dagli algoritmi, almeno nei compiti di screening delle lesioni della pelle. I risultati dell’ultima competizione organizzata dall’International Skin Imaging Collaboration ridimensionano queste aspettative e richiamano all’importanza di valutare le perfomance di questi algoritmi con dati realistici prima di introdurli nella pratica clinica. Gli algoritmi sono sì più accurati della media dei dermatologi coinvolti nella sfida, ma molto meno di quello che si pensava e tranne quando incontrano lesioni che non hanno mai visto prima.
A febbraio del 2017 la copertina della rivista Nature recava il titolo “Lesions Learnt”, il messaggio che ci saremmo aspettati di leggere sullo schermo di un computer se il risultato descritto dalla prestigiosa rivista scientifica fosse diventato il soggetto di un film hollywoodiano. Un gruppo di ricercatori, informatici e dermatologi, a pagina 115 di quel numero, descriveva i risultati ottenuti da un algoritmo di machine learning nel diagnosticare nove diverse categorie di malattie della pelle, sia benigne che maligne, in circa duemila immagini acquisite con dermatoscopio. Il dermatoscopio è costituito da una lente e una sorgente di luce che può anche essere polarizzata. Viene utilizzato dopo aver applicato sulla pelle un gel, per evitare che lo strato lipidico dell’epidermide rifletta la luce. In questo modo permette di guardare fino ai primi strati del derma, aumentando notevolmente la capacità di diagnosticare lesioni maligne rispetto all’analisi a occhio nudo.
L’algoritmo, una rete neurale profonda sviluppata da Google e pre-allenata su oltre un milione di immagine generiche, era stato poi allenato per questo compito speciale su un database di 130 mila immagini e si era dimostrato più accurato nel diagnosticare i novi tipi di lesione rispetto a una ventina di dermatologi esperti. L’entusiasmo degli autori era tangibile nelle conclusioni del lavoro dove prospettavano una democratizzazione della diagnosi dermatologica. Scrivevano che “equipaggiati con reti neurali profonde, i cellulari possono estendere il raggio d’azione dei dermatologi al di fuori degli ambulatori. Si prevede che entro il 2021 esisteranno 6,3 miliardi di abbonamenti a smartphone che quindi potranno fornire un accesso universale a basso costo a diagnosi vitali.”
Nel 2020 sono stati diagnosticati nel mondo 324 mila casi di melanoma, la forma più aggressiva di tumore della pelle, e le morti associate a questa patologia nello stesso anno sono state 57 mila. L’incidenza dei melanomi è particolarmente elevata in paesi come Nuova Zelanda, Australia, Danimarca, Paesi Bassi e Norvegia. L’altra famiglia di tumori della pelle, basaliomi e carcinomi spinocellulari, sono meno aggressivi e probabilmente sottodiagnosticati perché trattabili facilmente con chirurgia e ablazione.
Alla copertina di Nature seguirono altri studi sul ruolo degli algoritmi nella diagnosi dei tumori della pelle. Per esempio, quello coordinato dal dermatologo Harald Kittler dell’ospedale universitario di Vienna e pubblicato su The Lancet Oncology a luglio del 2019. Il lavoro, che nasceva da una competizione internazionale organizzata nel 2018 dall’International Skin Imaging Collaboration, confermava la superiorità dei migliori algoritmi rispetto ai migliori dermatologi, ma introduceva una nota di cautela: “la differenza tra gli esperti umani e i primi tre algoritmi è stata significativamente inferiore per le immagini provenienti da fonti (istituzioni, ospedali, strumenti, ndr) non incluse nel database di allenamento” concludevano gli autori.
L’edizione successiva della competizione, che si è svolta nel 2019, ha voluto esplorare proprio questi aspetti. I risultati sono stati pubblicati alla fine di aprile sulla rivista The Lancet Digital Health. Al terzo posto si è qualificato un gruppo di ricercatori dell’AImageLab dell’Università di Modena e Reggio Emilia, coordinato da Costantino Grana, insieme ad Alberto Albiol dell'Università Politecnica di Valencia. «È una delle sfide sull’automazione della diagnostica per immagini meglio organizzate», commenta Grana, «le immagini su cui gli algoritmi in competizione verranno testati non vengono pubblicate fino a quando tutti i gruppi non hanno consegnato i loro sistemi e questo rende la valutazione molto più robusta.»
Gli oltre 160 algoritmi candidati sono stati valutati su due insiemi di immagini, uno raccolto presso la clinica dermatologica dell’Università di medicina di Vienna e l’altro all’Ospedale Clinico di Barcellona. Rispetto al secondo, le immagini del primo campione riflettono meno le variazioni di qualità dell'immagine osservate nella pratica clinica. Dunque, i ricercatori hanno usato questi due campioni per capire di quanto si riducesse l’accuratezza delle diagnosi algoritmiche considerando immagini più realistiche.
Cosa si intende per più realistiche? Presenza di croste o ulcerazioni sopra la lesione, peli o capelli, segni di penna, assenza di pigmentazione in alcuni casi. Il database raccolto a Barcellona presenta questi “disturbi” in una percentuale di immagini maggiore rispetto a quello dell’Università di medicina di Vienna.
Come misura di accuratezza della diagnosi, i ricercatori hanno usato una media pesata delle sensibilità degli algoritmi rispetto alle diverse classi di lesioni. Ricordiamo che la sensibilità è la percentuale di lesioni di una certa classe correttamente identificate dall’algoritmo. Occorre precisare che gli algoritmi che hanno partecipato alla competizione non assegnavano a ciascuna immagine una diagnosi unica. Per ognuno dei novi tipi di lesione che erano stati addestrati a riconoscere, indicavano una percentuale. Per esempio melanoma al 95%, neo al 10%, basalioma al 5% e così via. Per calcolare la sensibilità i ricercatori hanno preso la diagnosi con la percentuale più elevata.
Il migliore algoritmo, sviluppato dal DAISYlab dell’Università di Amburgo, ha ottenuto in media un’accuratezza dell’82% sul dataset di Vienna e del 60% su quello di Barcellona. In media gli algortimi perdono il 22% di accuratezza passando dall’uno all’altro dataset.
L’impatto di croste, ulcerazioni, pigmentazione, peli o capelli dipende dal tipo di lesione da identificare. Quelle che tipicamente si presentano pigmentate, come nei e melanomi, sono classificate in modo errato più frequentemente se si presentano non pigmentate. Un melanoma non pigmentato, per esempio, viene classificato come tale dai migliori 25 algoritmi solo nel 46% dei casi e nel 23% dei casi viene invece riconosciuto come basalioma. I melanomi pigmentati invece vengono identificati correttamente nel 71% dei casi. La presenza di capelli sulla lesione incide meno, tranne che per la cheratosi solare, una lesione pre-cancerosa causata dall’esposizione ai raggi UV e particolarmente frequente negli anziani. Anche la posizione sul corpo incide sulla capacità degli algoritmi di classificare correttamente la lesione, soprattutto per quelle che si trovano più frequentemente in zone del corpo esposte al sole.
Infine, anche lo strumento con cui è stata raccolta l’immagine fa la differenza. Considerando le immagini acquisite con il sistema MoleMax, sviluppato e brevettato dall’Università di Vienna, i migliori 25 algoritmi hanno identificato correttamente il 99% dei nei ma nessun melanoma. Questo è probabilmente dovuto al fatto che circa il 20% delle lesioni acquisite con questo strumento sono nei mentre i melanomi rappresentano meno dell’1%.
L’accuratezza scende ancora se si considerano anche le immagini che raffiguravano un tipo di lesione non contenuta nelle immagini di allenamento. Questa è una delle peculiarità della competizione di quest’anno. Ai partecipanti è stato chiesto di progettare degli algoritmi in grado di “fallire in sicurezza”, ovvero di saper riconoscere le immagini che contenevano lesioni che non avevano mai visto prima e attribuirle a una categoria sconosciuta. Tra i primi 25 algoritmi in classifica, la categoria non presente nelle immagini di addestramento è stata etichettata correttamente solo nell’11% dei casi. Nel 33% dei casi queste immagini sono state assegnate alla categoria dei basaliomi, nell’8% come melanoma, e nel 7% come carcinoma cutaneo spinocellulare.
Gli autori dell’articolo scrivono che “questo risultato mette in luce i problemi di sicurezza legati all'impiego di algoritmi automatizzati in ambito clinico e la necessità di progettare metodi migliori per identificare immagini al di fuori dell'area di competenza di un algoritmo, al fine di evitare biopsie non necessarie o melanomi mancati, che si sarebbero verificati se fossero stati impiegati gli algoritmi testati in questo lavoro.”
«Noi ci siamo concentrati particolarmente su questo compito, ma il risultato non è stato soddisfacente. A posteriori abbiamo capito che il nostro algoritmo avrebbe beneficiato di una maggiore considerazione del sito della lesione», ha commentato Grana.
Gli algoritmi sono stati poi confrontati con i dermatologi esperti su circa 80 gruppi di 30 immagini dermoscopiche. In media le classificazioni corrette dei dermatologi sono state 16 su 30, mentre il miglior algoritmo ne ha indovinate 19 su 30. Nella classificazione dei melanomi, l’accuratezza degli esperti è superiore alla media degli algoritmi (62% contro 58%). Tuttavia, se si considerano i migliori tre algoritmi, questi vincono sui dermatologi esperti, con una sensibilità nella classificazione dei melanomi del 70%. Anche su dermatofibromi, basaliomi e carcinomi spinocellulari, i migliori tre algoritmi battono in sensibilità i dermatologi esperti. Tuttavia, nell’individuazione della categoria non inclusa nei dati di allenamento, gli algoritmi falliscono miseramente rispetto agli umani, con una sensibilità del 6% contro il 26%. Scrivono gli autori “per quello che ne sappiamo, questo studio è il primo a identificare un gruppo di lesioni, la categoria non inclusa nei dati di allenamento, per la quale i dermatologi esperti superano gli algoritmi.”
Se vi chiedete se alcuni di questi algoritmi siano già entrati, silenziosamente, nella pratica clinica, non è facile dare una risposta. «Le società che commercializzano i dermatoscopi offrono anche software per l’acquisizione e l’archiviazione delle immagini», dice Grana, «alcuni di questi sistemi implementano lo schema ABCDE (asimmetria, bordi, colore, diametro, evoluzione), altri hanno delle reti neurali che permettono classificazioni binarie, benigne-maligne. Chiaramente è difficile dire di quali algoritmi si tratti e come i dermatologi ne considerino le indicazioni nel formulare la diagnosi.»
Il messaggio che arriva dalla ISIC Grand Challenge del 2019 però è chiaro. Sono state identificate “carenze specifiche e problemi di sicurezza nei sistemi diagnostici di intelligenza artificiale per il cancro della pelle che dovrebbero essere affrontate nei futuri protocolli di valutazione diagnostica per migliorare la sicurezza e l'affidabilità nella pratica clinica.” Un’analisi delle prestazioni degli algoritmi su campioni stratificati rispetto “a varie caratteristiche, come la fonte dell'immagine, il sito anatomico, gli attributi dell'immagine e le caratteristiche cliniche, aiuterà le parti interessate a capire come impiegare gli algoritmi negli studi prospettici.”

